发布于
- 24 分钟阅读
代码会说话:基于Spoon框架的Java代码分析与图谱构建 - 对话Java代码库AI Agent系列(一)
代码会说话:基于Spoon框架的Java代码分析与图谱构建 - 对话Java代码库AI Agent系列(一)
1. 引言
在软件开发过程中,随着项目规模的不断扩大,代码库变得越来越复杂,开发团队常常面临着理解代码结构、追踪依赖关系、评估重构影响等挑战。静态代码分析工具作为开发者的得力助手,能够帮助我们深入理解代码库的内部结构,发现潜在问题,并为架构决策提供数据支持。
传统的代码分析方法往往局限于特定维度,如仅关注类继承关系或方法调用,难以提供全面的代码洞察。而且,随着微服务架构和分布式系统的普及,跨模块、跨服务的依赖分析变得尤为重要。这就需要一个能够从多个维度分析代码,并将结果以直观方式呈现的工具。
本文将介绍一个基于Spoon框架的Java代码分析与可视化系统,该系统能够自动分析Java项目的结构信息、依赖关系和调用图谱,并将分析结果存储为图数据库,便于后续查询和可视化。通过这个系统,开发团队可以:
- 直观了解项目的整体结构和模块划分
- 追踪方法调用链和依赖关系
- 识别API端点及其触发的业务逻辑
- 发现潜在的代码质量问题
- 评估重构或修改的影响范围
无论是新加入项目的开发者快速熟悉代码库,还是架构师进行系统分析和优化,这个工具都能提供有价值的帮助。接下来,我们将深入探讨这个系统的架构设计、核心功能实现以及实际应用场景。
2. 系统架构概述
2.1 整体架构设计
该Java代码分析与可视化系统采用了模块化的分层架构,主要由四个核心层次组成:
- 代码解析层:基于Spoon框架,负责将Java源代码解析为抽象语法树(AST)
- 分析处理层:包含多个专用处理器,负责从AST中提取各类信息
- 数据存储层:将分析结果以CSV格式存储,并转换为图数据库
- 可视化展示层:基于图数据库查询结果进行可视化展示
整个系统的工作流程如下图所示:
+----------------+ +----------------+ +----------------+ +----------------+
| | | | | | | |
| Java源代码项目 +---->+ Spoon解析引擎 +---->+ 多维度分析处理 +---->+ CSV数据输出 |
| | | | | | | |
+----------------+ +----------------+ +----------------+ +----------------+
|
v
+----------------+ +----------------+
| | | |
| 可视化展示 <-----+ KuzuDB图数据库 |
| | | |
+----------------+ +----------------+2.2 核心组件与数据流
系统的核心组件及其职责如下:
- JavaCodeAnalyzer:系统入口类,负责初始化环境、配置分析器和协调整个分析流程
- 处理器组件群:一系列基于Spoon框架的处理器,各自负责特定类型的代码元素分析
- CommentExtractor:提取和清理代码注释的工具类
- CsvWriter:将分析结果写入CSV文件的工具类
- create_graph.py:Python脚本,负责将CSV数据导入KuzuDB图数据库
数据在系统中的流转路径为:
Java源代码 → Spoon AST → 处理器分析 → 内存数据结构 → CSV文件 → KuzuDB图数据库具体来说:
- JavaCodeAnalyzer首先扫描项目结构,收集所有模块和源码目录
- 通过Spoon框架将源码解析为AST
- 注册并运行各种处理器,处理器遍历AST并提取信息
- 处理器将提取的信息通过CsvWriter存储到内存中
- 分析完成后,CsvWriter将内存中的数据写入CSV文件
- 最后,create_graph.py脚本读取CSV文件,将数据导入KuzuDB图数据库
2.3 技术栈选择
系统采用了以下关键技术:
-
Spoon框架:一个强大的Java源码分析和转换框架,提供了丰富的API用于操作AST
- 优势:提供完整的Java语法支持,能够精确解析Java代码结构
- 应用:系统的所有处理器都基于Spoon的访问者模式实现
-
KuzuDB:一个高性能的图数据库,专为复杂关系数据设计
- 优势:支持高效的图查询,适合代码结构和依赖关系的存储与查询
- 应用:存储代码实体(模块、类、方法、API端点)及其关系
-
CSV作为中间存储格式:
- 优势:简单、通用、易于处理和调试
- 应用:作为Java分析结果和图数据库之间的桥梁
-
Java与Python混合架构:
- 优势:结合Java的强类型和Python的数据处理能力
- 应用:Java负责代码分析,Python负责数据导入和后续处理
2.4 模块间协作机制
系统各模块通过以下机制协作:
-
共享数据结构:
// JavaCodeAnalyzer.java中定义的共享数据结构 private static final Map<String, Set<String>> callEdges = new HashMap<>(); private static final List<List<String>> callChains = new ArrayList<>(); private static final List<ModuleInfo> moduleInfoList = new ArrayList<>(); private static final Map<String, String> methodMap = new HashMap<>(); private static final Map<Long, String> classIdMap = new HashMap<>(); -
处理器注册与执行:
// 处理器注册示例 spoon.addProcessor(new ClassProcessor(moduleInfoList, classIdMap)); spoon.addProcessor(new MethodProcessor(methodMap, classIdMap)); spoon.addProcessor(new MethodCallProcessor(callEdges, callChains, methodMap)); -
统一数据输出接口:
// 通过CsvWriter统一输出数据 CsvWriter.addClass(classId, className, packageName, type, comment, filePath); CsvWriter.addMethod(methodId, methodFullName, returnType, modifiers, comment, startLine, endLine); CsvWriter.addCalls(callerId, calleeId);
这种设计使得系统具有良好的可扩展性,可以通过添加新的处理器来支持更多类型的代码分析,而无需修改整体架构。
3. 核心功能实现
本节将深入探讨系统的核心功能实现,包括代码解析与AST构建、各类信息提取、调用关系分析、API端点识别以及代码质量检测等方面。
3.1 代码解析与AST构建
系统基于Spoon框架进行Java源码解析,将源代码转换为抽象语法树(AST),为后续分析提供基础。
3.1.1 Spoon环境初始化
在JavaCodeAnalyzer类中,我们可以看到Spoon环境的初始化过程:
// 初始化 Spoon 并分析代码
Launcher spoon = new Launcher();
spoon.getEnvironment().setNoClasspath(true); // 忽略缺失的依赖(简化示例)
spoon.getEnvironment().setCommentEnabled(false); // 减少内存占用
spoon.getEnvironment().setIgnoreDuplicateDeclarations(true); // 忽略重复声明
spoon.getEnvironment().setAutoImports(true); // 自动处理导入
spoon.getEnvironment().debugMessage("Analysis started");
spoon.setSourceOutputDirectory("build/spooned");这里的关键配置包括:
setNoClasspath(true):允许在不完整的类路径下分析代码,适用于大型项目setCommentEnabled(false):优化内存使用,注释通过专门的CommentExtractor处理setIgnoreDuplicateDeclarations(true):处理可能的重复声明问题setAutoImports(true):自动处理导入语句
3.1.2 多模块项目支持
系统支持Maven多模块项目的分析,通过递归查找所有包含pom.xml的目录:
// 查找 Maven 多模块项目的源码目录和模块信息
private static List<ModuleInfo> findMavenSourceDirs(String projectPath, String src) throws Exception {
Files.walk(Paths.get(projectPath))
.filter(path -> path.resolve("pom.xml").toFile().exists())
.forEach(modulePath -> {
try {
ModuleInfo moduleInfo = extractModuleName(modulePath.toString());
moduleInfo.setModuleId(Math.abs(moduleInfo.getArtifactId().hashCode()));
Path srcDir = modulePath.resolve(src);
if (srcDir.toFile().exists()) {
moduleInfo.setSrcDir(srcDir.toString());
}
moduleInfoList.add(moduleInfo);
} catch (Exception e) {
log.error("findMavenSourceDirs Error", e);
}
});
return moduleInfoList;
}这段代码使用Java 8的Stream API遍历项目目录,找出所有包含pom.xml的路径,并从中提取模块信息和源码目录。
3.2 类与方法信息提取
3.2.1 类信息提取
ClassProcessor负责提取类的基本信息和类型判断:
public void process(CtClass<?> ctClass) {
// 检测类的类型(Servlet、Controller等)
if (ctClass.getSuperclass() != null &&
ctClass.getSuperclass().getQualifiedName().equals(HttpServlet.class.getName())) {
System.out.println("Servlet入口: " + ctClass.getQualifiedName());
}
// 其他类型判断...
String className = ctClass.getQualifiedName();
String packageName = ctClass.getPackage() != null ?
ctClass.getPackage().getQualifiedName() : "(default package)";
String comment = CommentExtractor.extractComment(ctClass);
String type = "OTHER";
// 类型判断逻辑...
// 生成classId并存储类信息
long classId = Math.abs(className.hashCode());
CsvWriter.addClass(classId, className, packageName, type, comment, filePath);
classIdMap.put(classId, "");
// 类与模块关系
for (ModuleInfo moduleInfo : moduleInfoList) {
if (filePath.contains(moduleInfo.getModulePath())) {
CsvWriter.addBelongsTo(classId, moduleInfo.getModuleId());
}
}
}这里的关键点包括:
- 类型识别:通过继承关系和注解识别Servlet、Controller等特殊类型
- 注释提取:使用CommentExtractor提取和清理类注释
- ID生成:使用类全名的哈希值作为唯一标识
- 模块关联:建立类与所属模块的关系
3.2.2 方法信息提取
MethodProcessor负责提取方法的详细信息:
public void process(CtMethod<?> method) {
// 方法基本信息(包含参数类型)
String methodName = method.getDeclaringType().getQualifiedName() + "." + method.getSimpleName();
String methodFullName = methodName +
method.getParameters().stream()
.map(p -> p.getType().toString())
.collect(Collectors.joining(",", "(", ")"));
String returnType = method.getType().toString();
String comment = CommentExtractor.extractComment(method);
// 将 ModifierKind 枚举转换为字符串列表
List<String> modifierNames = method.getModifiers().stream()
.map(ModifierKind::name)
.collect(Collectors.toList());
// 使用逗号拼接修饰符
String modifiers = String.join(",", modifierNames);
// 生成methodId和存储方法信息
long methodId = Math.abs(methodFullName.hashCode());
long classId = Math.abs(method.getDeclaringType().getQualifiedName().hashCode());
if (classIdMap.containsKey(classId)) {
CsvWriter.addMethod(
methodId, methodFullName, returnType, modifiers, comment,
String.valueOf(method.getPosition().getLine()),
String.valueOf(method.getPosition().getEndLine()));
// 添加类与方法关系
CsvWriter.addHasMethod(classId, methodId);
methodMap.put(methodFullName, "0");
}
}这段代码展示了如何:
- 构建完整方法签名(包括参数类型)
- 提取返回类型和修饰符
- 记录方法的行号范围
- 建立类与方法的从属关系
3.3 调用关系与依赖分析
3.3.1 方法调用分析
MethodCallProcessor是系统的核心组件之一,负责分析方法调用关系:
public void process(CtInvocation<?> invocation) {
try {
// 获取当前方法的签名
CtMethod<?> callerMethod = invocation.getParent(CtMethod.class);
if (callerMethod == null) return;
String caller = getMethodSignature(callerMethod);
String callee = getInvocationSignature(invocation);
if (methodMap.containsKey(callee) && methodMap.containsKey(caller)) {
// 记录调用关系
callEdges.computeIfAbsent(caller, k -> new HashSet<>()).add(callee);
// 记录调用关系到CSV
long callerId = Math.abs(caller.hashCode());
long calleeId = Math.abs(callee.hashCode());
CsvWriter.addCalls(callerId, calleeId);
// 解析完整调用链(如 a().b().c())
List<String> chain = new ArrayList<>();
CtInvocation<?> current = invocation;
while (current != null) {
chain.add(0, getInvocationSignature(current));
current = current.getTarget() instanceof CtInvocation ?
(CtInvocation<?>) current.getTarget() : null;
}
callChains.add(chain);
}
} catch (Exception e) {
log.error("Method Call process Error", e);
}
}这段代码的亮点包括:
- 提取调用者和被调用者的完整签名
- 构建调用关系图(callEdges)
- 识别和记录方法调用链(如链式调用)
- 使用哈希值作为方法ID,确保一致性
3.3.2 类关系分析
ClassRelationProcessor负责分析类之间的继承和实现关系:
public void process(CtClass<?> ctClass) {
if (ctClass.getPosition().getFile() != null) {
// 继承关系
if (ctClass.getSuperclass() != null) {
String superClassName = ctClass.getSuperclass().getQualifiedName();
// 记录调用关系到CSV
long childClassId = Math.abs(ctClass.getQualifiedName().hashCode());
long superClassId = Math.abs(superClassName.hashCode());
CsvWriter.addExtends(childClassId, superClassId);
// 其他处理...
}
}
// 接口实现
ctClass.getSuperInterfaces().forEach(i -> {
// 处理接口实现关系
long superClassId = Math.abs(i.getQualifiedName().hashCode());
CsvWriter.addImplements(
Math.abs(ctClass.getQualifiedName().hashCode()),
Math.abs(i.getQualifiedName().hashCode())
);
// 其他处理...
});
}这段代码展示了如何:
- 识别类的继承关系
- 识别接口实现关系
- 将这些关系存储为图数据库的边
3.3.3 包依赖分析
ReferenceProcessor用于检测包之间的依赖关系,特别是循环依赖:
public void process(CtPackage element) {
CtPackageReference pack = element.getReference();
Set<CtPackageReference> refs = new HashSet<>();
for (CtType t : element.getTypes()) {
List<CtTypeReference<?>> listReferences = Query.getReferences(t,
new ReferenceTypeFilter<>(CtTypeReference.class));
for (CtTypeReference<?> tref : listReferences) {
if (tref.getPackage() != null && !tref.getPackage().equals(pack)) {
if (ignoredTypes.contains(tref))
continue;
refs.add(tref.getPackage());
}
}
}
if (!refs.isEmpty()) {
packRefs.put(pack, refs);
}
}
// 检测循环依赖
@Override
public void processingDone() {
for (CtPackageReference p : packRefs.keySet()) {
Stack<CtPackageReference> path = new Stack<>();
path.push(p);
scanDependencies(path);
}
}这段代码的关键点是:
- 收集包之间的引用关系
- 使用深度优先搜索检测循环依赖
- 记录发现的循环依赖路径
3.4 API端点识别
APIEndpointProcessor专门用于识别REST API端点:
public void process(CtMethod<?> method) {
// 方法基本信息
String methodName = method.getDeclaringType().getQualifiedName() + "." + method.getSimpleName();
String methodFullName = /* 构建完整方法签名 */;
String comment = CommentExtractor.extractComment(method);
long methodId = Math.abs(methodFullName.hashCode());
long classId = Math.abs(method.getDeclaringType().getQualifiedName().hashCode());
// API端点处理
for (Class<? extends Annotation> annotation : MAPPING_ANNOTATIONS) {
if (methodMap.containsKey(methodFullName) && classIdMap.containsKey(classId)) {
if (method.getAnnotation(annotation) != null) {
String path = extractPathFromAnnotation(method, annotation);
long apiEndpointId = Math.abs((path + "|" + methodName).hashCode());
CsvWriter.addApiEndpoint(apiEndpointId, path, methodName, comment);
CsvWriter.addTriggers(apiEndpointId, methodId);
CsvWriter.addExposes(classId, apiEndpointId);
// 控制流分析
if (method.getBody() != null) {
ControlFlowBuilder builder = new ControlFlowBuilder();
// 配置控制流分析选项
EnumSet<NaiveExceptionControlFlowStrategy.Options> options;
options = EnumSet.of(NaiveExceptionControlFlowStrategy.Options.ReturnWithoutFinalizers);
builder.setExceptionControlFlowStrategy(new NaiveExceptionControlFlowStrategy(options));
ControlFlowGraph graph = builder.build(method);
}
break;
}
}
}
}这段代码展示了如何:
- 识别Spring MVC的各种映射注解(@RequestMapping, @GetMapping等)
- 提取API路径信息
- 建立API端点与方法的触发关系
- 分析API方法的控制流
3.5 代码质量检测
系统包含多个用于代码质量检测的处理器:
3.5.1 空Catch块检测
public class CatchProcessor extends AbstractProcessor<CtCatch> {
public final List<CtCatch> emptyCatchs = new ArrayList<>();
@Override
public boolean isToBeProcessed(CtCatch candidate) {
return candidate.getBody().getStatements().isEmpty();
}
@Override
public void process(CtCatch element) {
getEnvironment().report(this, Level.INFO,
"empty catch clause at " + element.getPosition().toString());
emptyCatchs.add(element);
}
}3.5.2 空方法体检测
public class EmptyMethodBodyProcessor extends AbstractProcessor<CtMethod<?>> {
public final List<CtMethod> emptyMethods = new ArrayList<>();
public void process(CtMethod<?> element) {
if (element.getParent(CtClass.class) != null &&
!element.getModifiers().contains(ModifierKind.ABSTRACT) &&
element.getBody().getStatements().isEmpty()) {
emptyMethods.add(element);
}
}
}3.5.3 工厂模式使用检测
public class FactoryProcessor extends AbstractProcessor<CtConstructorCall<?>> {
public List<CtConstructorCall> listWrongUses = new ArrayList<>();
private CtTypeReference factoryTypeRef;
// 检测是否绕过工厂直接使用构造函数
public void process(CtConstructorCall<?> newClass) {
// 跳过工厂创建
if (newClass.getExecutable().getDeclaringType().isSubtypeOf(getFactoryType()))
return;
// 跳过在工厂中的创建
if (newClass.getParent(CtClass.class).isSubtypeOf(getFactoryType()))
return;
// 只报告应由工厂创建的类型
for (CtTypeReference<?> t : getCreatedTypes()) {
if (newClass.getType().isSubtypeOf(t)) {
this.listWrongUses.add(newClass);
}
}
}
}这些处理器共同构成了系统的代码质量检测功能,可以帮助开发团队发现潜在的代码问题。
4. 数据处理与可视化
本节将详细介绍系统的数据处理流程和可视化方案,包括CSV数据存储格式、图数据库模型设计、数据导入转换过程以及可视化展示方案。
4.1 CSV数据存储格式
系统使用CSV作为中间数据存储格式,通过CsvWriter类将分析结果写入CSV文件。这种格式简单、通用,便于调试和后续处理。
4.1.1 CSV文件结构
系统生成的CSV文件分为两大类:
-
节点表:存储实体信息
module.csv:模块信息class.csv:类信息method.csv:方法信息apiendpoint.csv:API端点信息
-
关系表:存储实体间的关系
belongs_to.csv:类-模块关系has_method.csv:类-方法关系calls.csv:方法调用关系extends.csv:类继承关系implements.csv:接口实现关系exposes.csv:类-API端点关系triggers.csv:API端点-方法关系
4.1.2 CsvWriter实现
CsvWriter类负责将分析结果写入CSV文件,其核心实现如下:
public class CsvWriter {
private static final Map<String, List<String[]>> csvData = new HashMap<>();
static {
csvData.put("Module", new ArrayList<>());
csvData.put("Class", new ArrayList<>());
csvData.put("Method", new ArrayList<>());
csvData.put("APIEndpoint", new ArrayList<>());
csvData.put("BELONGS_TO", new ArrayList<>());
csvData.put("HAS_METHOD", new ArrayList<>());
csvData.put("CALLS", new ArrayList<>());
csvData.put("EXTENDS", new ArrayList<>());
csvData.put("IMPLEMENTS", new ArrayList<>());
csvData.put("EXPOSES", new ArrayList<>());
csvData.put("TRIGGERS", new ArrayList<>());
}
// 添加节点和关系的方法
public static void addClass(long classId, String className, String packageName,
String type, String comment, String filePath) {
csvData.get("Class").add(new String[]{
String.valueOf(classId), className, packageName, type, comment, filePath
});
}
// 其他添加方法...
// 写入所有CSV文件
public static void writeAll(Path outputDir) throws Exception {
for (String table : csvData.keySet()) {
Path file = outputDir.resolve(table.toLowerCase() + ".csv");
try (BufferedWriter writer = new BufferedWriter(new FileWriter(file.toFile()))) {
// 写入表头
switch (table) {
case "Class":
writer.write("class_id,class_name,package_name,type,comment,file_path\n");
break;
// 其他表头...
}
// 写入数据
for (String[] row : csvData.get(table)) {
writer.write(Arrays.stream(row)
.map(f -> f.contains(",") ? "\"" + f + "\"" : f)
.collect(Collectors.joining(",")) + "\n");
}
}
}
}
}CsvWriter采用了内存缓冲的设计,所有分析结果首先存储在内存中的Map结构里,分析完成后一次性写入文件,这种设计提高了性能并简化了实现。
4.2 图数据库模型设计
系统使用KuzuDB作为图数据库,将代码结构和关系表示为图模型。
4.2.1 节点表设计
图数据库中定义了四种主要节点类型:
# 模块节点
conn.execute(
"CREATE NODE TABLE IF NOT EXISTS Module (module_id INT64, module_name STRING, project_path STRING, PRIMARY KEY (module_id))"
)
# 类节点
conn.execute(
"CREATE NODE TABLE IF NOT EXISTS Class(class_id INT64, class_name STRING, package_name STRING, type STRING, comment STRING, file_path STRING, PRIMARY KEY(class_id))"
)
# 方法节点
conn.execute(
"CREATE NODE TABLE IF NOT EXISTS Method(method_id INT64, method_full_name STRING, return_type STRING, modifiers STRING, comment STRING, start_line STRING, end_line STRING, PRIMARY KEY(method_id))"
)
# API端点节点
conn.execute(
"CREATE NODE TABLE IF NOT EXISTS APIEndpoint(api_endpoint_id INT64, endpoint_url STRING, method_full_name STRING, description STRING, PRIMARY KEY(api_endpoint_id))"
)每种节点类型都有其特定属性,如:
- Module:模块ID、名称、项目路径
- Class:类ID、类名、包名、类型、注释、文件路径
- Method:方法ID、完整方法名、返回类型、修饰符、注释、起始行、结束行
- APIEndpoint:端点ID、URL路径、方法全名、描述
4.2.2 关系表设计
图数据库中定义了七种主要关系类型:
# 类属于模块
conn.execute("CREATE REL TABLE IF NOT EXISTS BELONGS_TO (FROM Class TO Module)")
# 类拥有方法
conn.execute("CREATE REL TABLE IF NOT EXISTS HAS_METHOD (FROM Class TO Method)")
# 方法调用方法
conn.execute("CREATE REL TABLE IF NOT EXISTS CALLS (FROM Method TO Method)")
# 类继承类
conn.execute("CREATE REL TABLE IF NOT EXISTS EXTENDS (FROM Class TO Class)")
# 类实现接口
conn.execute("CREATE REL TABLE IF NOT EXISTS IMPLEMENTS (FROM Class TO Class)")
# 类暴露API端点
conn.execute("CREATE REL TABLE IF NOT EXISTS EXPOSES (FROM Class TO APIEndpoint)")
# API端点触发方法
conn.execute("CREATE REL TABLE IF NOT EXISTS TRIGGERS (FROM APIEndpoint TO Method)")这些关系构成了代码结构的完整图谱,可以回答诸如”哪些方法调用了特定方法”、“特定API端点触发了哪些方法”等复杂查询。
4.3 数据导入与转换
系统使用Python脚本create_graph.py将CSV数据导入KuzuDB图数据库:
import shutil
import kuzu
DB_PATH = "./kuzudb"
shutil.rmtree(DB_PATH, ignore_errors=True)
db = kuzu.Database(DB_PATH)
conn = kuzu.Connection(db)
# 创建节点和关系表
# ...(前面已展示)
# 导入CSV数据
conn.execute(
"COPY Module FROM '/path/to/output/module.csv' (HEADER=true)"
)
conn.execute(
"COPY Class FROM '/path/to/output/class.csv' (HEADER=true)"
)
# 其他表导入...
print(f"Finished processing data and created Kuzu graph at the following path: {DB_PATH}")导入过程的关键点:
- 首先清空并重新创建数据库目录
- 创建数据库连接
- 定义节点和关系表结构
- 使用COPY命令从CSV文件批量导入数据
这种设计使得Java分析部分和图数据库构建部分解耦,便于独立开发和维护。
4.4 可视化展示方案
基于KuzuDB图数据库,系统可以支持多种可视化展示方案:
4.4.1 调用关系图
方法调用关系可以通过以下Cypher查询获取并可视化:
MATCH (caller:Method)-[:CALLS]->(callee:Method)
RETURN caller.method_full_name AS source, callee.method_full_name AS target这种查询可以生成方法调用网络图,展示方法间的调用关系。下图展示了一个实际项目的方法调用关系可视化效果:
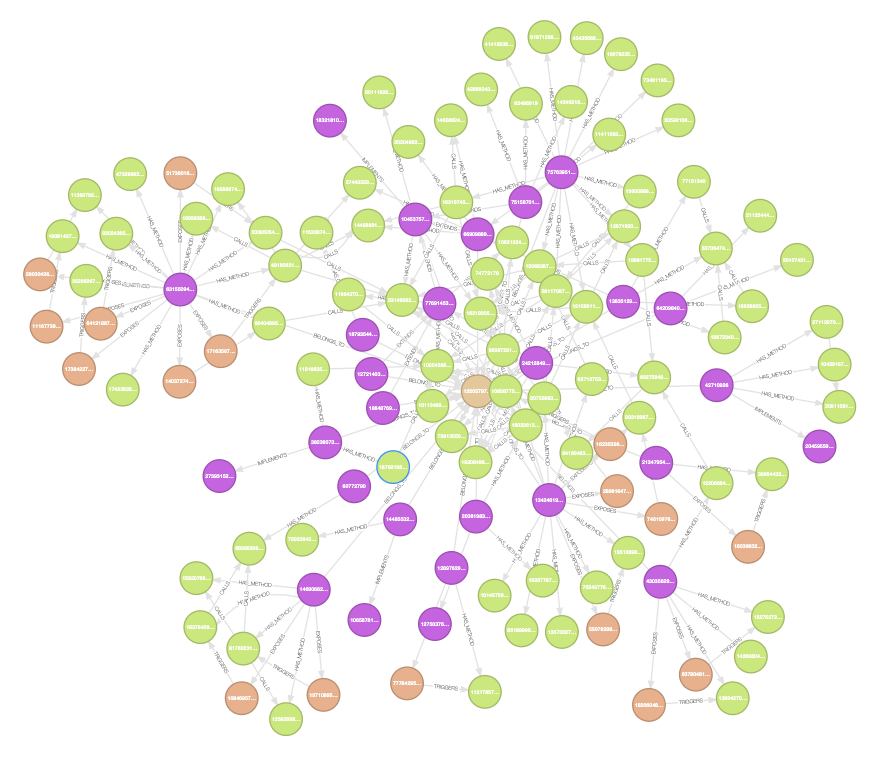
图4-1:Java代码方法调用关系可视化。不同颜色的节点代表不同类型的方法,连线表示调用关系。
4.4.2 类继承树
类继承关系可以通过以下Cypher查询获取并可视化:
MATCH (child:Class)-[:EXTENDS]->(parent:Class)
RETURN child.class_name AS child, parent.class_name AS parent这种查询可以生成类继承树,展示类的层次结构。
4.4.3 API依赖图
API端点及其依赖的方法可以通过以下Cypher查询获取:
MATCH (api:APIEndpoint)-[:TRIGGERS]->(method:Method)
RETURN api.endpoint_url AS api_url, method.method_full_name AS method_name这种查询可以生成API依赖图,展示API端点与后端方法的关系。
4.4.4 模块依赖图
模块间的依赖关系可以通过类间调用关系推导:
MATCH (c1:Class)-[:BELONGS_TO]->(m1:Module),
(c2:Class)-[:BELONGS_TO]->(m2:Module),
(c1)-[:HAS_METHOD]->(caller:Method),
(c2)-[:HAS_METHOD]->(callee:Method),
(caller)-[:CALLS]->(callee)
WHERE m1.module_id <> m2.module_id
RETURN m1.module_name AS source_module,
m2.module_name AS target_module,
count(*) AS dependency_strength这种查询可以生成模块依赖热力图,展示模块间的依赖强度。
通过这些可视化方案,开发团队可以直观地理解代码结构、依赖关系和潜在问题,为代码优化和重构提供依据。
5. 附录:运行KuzuDB可视化界面
为了方便查看和探索代码分析结果,KuzuDB提供了一个名为KuzuDB Explorer的可视化界面工具。以下是启动该工具的Docker命令:
docker run -p 8000:8000 \
-v ./kuzudb:/database \
--rm kuzudb/explorer:latest该命令会:
- 在本地8000端口启动KuzuDB Explorer
- 将本地的
./kuzudb目录挂载到容器的/database路径 - 容器停止后自动删除(
--rm参数)
启动后,可以通过浏览器访问http://localhost:8000来使用可视化界面,执行Cypher查询并查看结果图形。