Published on
- 19 min read
Code Speaks: Java Code Analysis and Graph Construction Based on Spoon Framework - Dialogue with Java Codebase AI Agent Series (Part 1)
Code Speaks: Java Code Analysis and Graph Construction Based on Spoon Framework - Dialogue with Java Codebase AI Agent Series (Part 1)
1. Introduction
In the process of software development, as the project scale continues to expand, the codebase becomes more complex, and development teams often face challenges such as understanding code structure, tracing dependencies, and assessing refactoring impacts. Static code analysis tools, as a powerful assistant for developers, can help us deeply understand the internal structure of the codebase, discover potential issues, and provide data support for architectural decisions.
Traditional code analysis methods are often limited to specific dimensions, such as focusing only on class inheritance or method calls, which are difficult to provide comprehensive code insights. Moreover, with the popularity of microservice architectures and distributed systems, cross-module and cross-service dependency analysis has become more important. This requires a tool that can analyze code from multiple dimensions and present the results in an intuitive way.
This article will introduce a Java code analysis and visualization system based on the Spoon framework. This system can automatically analyze the structure information, dependency relationships, and call graph of Java projects, and store the analysis results as a graph database for later queries and visualizations. Through this system, development teams can:
- Gain an intuitive understanding of the overall structure and module division of the project
- Trace method call chains and dependency relationships
- Identify API endpoints and the business logic they trigger
- Discover potential code quality issues
- Assess the scope of refactoring or modification
Whether it’s a new developer quickly familiarizing themselves with the codebase, or an architect conducting system analysis and optimization, this tool can provide valuable assistance. Next, we will delve into the system’s architecture design, core functionality implementation, and practical application scenarios.
2. System Architecture Overview
2.1 Overall Architecture Design
The Java code analysis and visualization system adopts a modular layered architecture, mainly consisting of four core layers:
- Code Parsing Layer:Based on the Spoon framework, responsible for parsing Java source code into an abstract syntax tree (AST)
- Analysis Processing Layer:Contains multiple specialized processors, responsible for extracting various information from the AST
- Data Storage Layer:Stores analysis results in CSV format and converts them to a graph database
- Visualization Display Layer:Based on the graph database, query results are visualized
The workflow of the entire system is shown in the following diagram:
+----------------+ +----------------+ +----------------+ +----------------+
| | | | | | | |
| Java源代码项目 +---->+ Spoon解析引擎 +---->+ 多维度分析处理 +---->+ CSV数据输出 |
| | | | | | | |
+----------------+ +----------------+ +----------------+ +----------------+
|
v
+----------------+ +----------------+
| | | |
| 可视化展示 <-----+ KuzuDB图数据库 |
| | | |
+----------------+ +----------------+2.2 Core Components and Data Flow
The core components and their responsibilities are as follows:
- JavaCodeAnalyzer:System entry class, responsible for initializing the environment, configuring the analyzer, and coordinating the entire analysis process
- Processor Component Group:A series of processors based on the Spoon framework, each responsible for analyzing specific types of code elements
- CommentExtractor:A tool class for extracting and cleaning code comments
- CsvWriter:A tool class for writing analysis results to a CSV file
- create_graph.py:A Python script responsible for importing CSV data into a KuzuDB graph database
The data flow in the system is as follows:
Java source code → Spoon AST → Processor analysis → Memory data structure → CSV file → KuzuDB graph databaseSpecifically:
- JavaCodeAnalyzer first scans the project structure, collects all modules and source directories
- The source code is parsed into an AST by the Spoon framework
- Register and run various processors, and the processors traverse the AST and extract information
- The processors store the extracted information in memory through CsvWriter
- After the analysis is complete, CsvWriter writes the data in memory to a CSV file
- Finally, the create_graph.py script reads the CSV file and imports the data into the KuzuDB graph database
2.3 Technology Stack Selection
The system uses the following key technologies:
-
Spoon framework:A powerful Java source code analysis and transformation framework, providing rich APIs for operating on AST
- Advantage: Provides comprehensive Java syntax support, able to accurately parse Java code structure
- Application: All processors in the system are implemented based on the visitor pattern of Spoon
-
KuzuDB:A high-performance graph database designed for complex relational data
- Advantage: Supports efficient graph queries, suitable for storing and querying code entity (module, class, method, API endpoint) and their relationships
- Application: Store code entities (modules, classes, methods, API endpoints) and their relationships
-
CSV as an intermediate storage format:
- Advantage: Simple, universal, and easy to process and debug
- Application: As a bridge between Java analysis results and the graph database
-
Java and Python mixed architecture:
- Advantage: Combine the strong type of Java with the data processing ability of Python
- Application: Java is responsible for code analysis, and Python is responsible for data import and subsequent processing
2.4 Inter-module Collaboration Mechanism
The system’s modules collaborate through the following mechanisms:
-
Shared Data Structure:
// Shared data structure defined in JavaCodeAnalyzer.java private static final Map<String, Set<String>> callEdges = new HashMap<>(); private static final List<List<String>> callChains = new ArrayList<>(); private static final List<ModuleInfo> moduleInfoList = new ArrayList<>(); private static final Map<String, String> methodMap = new HashMap<>(); private static final Map<Long, String> classIdMap = new HashMap<>(); -
Processor Registration and Execution:
// Example of processor registration spoon.addProcessor(new ClassProcessor(moduleInfoList, classIdMap)); spoon.addProcessor(new MethodProcessor(methodMap, classIdMap)); spoon.addProcessor(new MethodCallProcessor(callEdges, callChains, methodMap)); -
Uniform Data Output Interface:
// Unified data output interface CsvWriter.addClass(classId, className, packageName, type, comment, filePath); CsvWriter.addMethod(methodId, methodFullName, returnType, modifiers, comment, startLine, endLine); CsvWriter.addCalls(callerId, calleeId);
This design makes the system highly extensible, allowing new processors to be added to support more types of code analysis without modifying the overall architecture.
3. Core Function Implementation
This section will delve into the core functionality implementation of the system, including code parsing and AST construction, various information extraction, call relationship analysis, API endpoint identification, and code quality detection.
3.1 Code Parsing and AST Construction
The system parses Java source code using the Spoon framework, converting the source code into an abstract syntax tree (AST), providing a foundation for subsequent analysis.
3.1.1 Spoon Environment Initialization
In the JavaCodeAnalyzer class, we can see the initialization process of the Spoon environment:
// Initialize the Spoon environment and analyze the code
Launcher spoon = new Launcher();
spoon.getEnvironment().setNoClasspath(true); // Ignore missing dependencies (simplified example)
spoon.getEnvironment().setCommentEnabled(false); // Reduce memory usage
spoon.getEnvironment().setIgnoreDuplicateDeclarations(true); // Ignore duplicate declarations
spoon.getEnvironment().setAutoImports(true); // Automatically handle imports
spoon.getEnvironment().debugMessage("Analysis started");
spoon.setSourceOutputDirectory("build/spooned");The key configurations include:
setNoClasspath(true):Allow analysis of code with incomplete classpath, suitable for large projectssetCommentEnabled(false):Optimize memory usage, comments are processed through a dedicated CommentExtractorsetIgnoreDuplicateDeclarations(true):Handle possible duplicate declaration issuessetAutoImports(true):Automatically handle import statements
3.1.2 Support for Multi-module Projects
The system supports the analysis of Maven multi-module projects, identifying all directories containing pom.xml:
// Find the source code directory and module information of the Maven multi-module project
private static List<ModuleInfo> findMavenSourceDirs(String projectPath, String src) throws Exception {
Files.walk(Paths.get(projectPath))
.filter(path -> path.resolve("pom.xml").toFile().exists())
.forEach(modulePath -> {
try {
ModuleInfo moduleInfo = extractModuleName(modulePath.toString());
moduleInfo.setModuleId(Math.abs(moduleInfo.getArtifactId().hashCode()));
Path srcDir = modulePath.resolve(src);
if (srcDir.toFile().exists()) {
moduleInfo.setSrcDir(srcDir.toString());
}
moduleInfoList.add(moduleInfo);
} catch (Exception e) {
log.error("findMavenSourceDirs Error", e);
}
});
return moduleInfoList;
}This code uses Java 8’s Stream API to traverse the project directory, find all paths containing pom.xml, and extract module information and source code directory from them.
3.2 Class and Method Information Extraction
3.2.1 Class Information Extraction
ClassProcessor is responsible for extracting basic information and type judgment of classes:
public void process(CtClass<?> ctClass) {
// Detect the type of the class (Servlet, Controller, etc.)
if (ctClass.getSuperclass() != null &&
ctClass.getSuperclass().getQualifiedName().equals(HttpServlet.class.getName())) {
System.out.println("Servlet entry: " + ctClass.getQualifiedName());
}
// Other type judgment...
String className = ctClass.getQualifiedName();
String packageName = ctClass.getPackage() != null ?
ctClass.getPackage().getQualifiedName() : "(default package)";
String comment = CommentExtractor.extractComment(ctClass);
String type = "OTHER";
// Type judgment logic...
// Generate classId and store class information
long classId = Math.abs(className.hashCode());
CsvWriter.addClass(classId, className, packageName, type, comment, filePath);
classIdMap.put(classId, "");
// Class and module relationship
for (ModuleInfo moduleInfo : moduleInfoList) {
if (filePath.contains(moduleInfo.getModulePath())) {
CsvWriter.addBelongsTo(classId, moduleInfo.getModuleId());
}
}
}The key points include:
- Type identification: Identify special types such as Servlet, Controller through inheritance and annotations
- Comment extraction: Use CommentExtractor to extract and clean class comments
- ID generation: Use the hash value of the class full name as the unique identifier
- Module association: Establish the relationship between the class and its所属模块
3.2.2 Method Information Extraction
MethodProcessor is responsible for extracting detailed information about methods:
public void process(CtMethod<?> method) {
// Basic information of the method (including parameter types)
String methodName = method.getDeclaringType().getQualifiedName() + "." + method.getSimpleName();
String methodFullName = methodName +
method.getParameters().stream()
.map(p -> p.getType().toString())
.collect(Collectors.joining(",", "(", ")"));
String returnType = method.getType().toString();
String comment = CommentExtractor.extractComment(method);
// Convert the ModifierKind enum to a list of strings
List<String> modifierNames = method.getModifiers().stream()
.map(ModifierKind::name)
.collect(Collectors.toList());
// Join modifiers with commas
String modifiers = String.join(",", modifierNames);
// Generate methodId and store method information
long methodId = Math.abs(methodFullName.hashCode());
long classId = Math.abs(method.getDeclaringType().getQualifiedName().hashCode());
if (classIdMap.containsKey(classId)) {
CsvWriter.addMethod(
methodId, methodFullName, returnType, modifiers, comment,
String.valueOf(method.getPosition().getLine()),
String.valueOf(method.getPosition().getEndLine()));
// Add class and method relationship
CsvWriter.addHasMethod(classId, methodId);
methodMap.put(methodFullName, "0");
}
}This code demonstrates how to:
- Build a complete method signature (including parameter types)
- Extract the return type and modifiers
- Record the line number range of the method
- Establish the relationship between the class and the method
3.3 Call Relationship and Dependency Analysis
3.3.1 Method Call Analysis
MethodCallProcessor is one of the core components of the system, responsible for analyzing method call relationships:
public void process(CtInvocation<?> invocation) {
try {
// Get the signature of the current method
CtMethod<?> callerMethod = invocation.getParent(CtMethod.class);
if (callerMethod == null) return;
String caller = getMethodSignature(callerMethod);
String callee = getInvocationSignature(invocation);
if (methodMap.containsKey(callee) && methodMap.containsKey(caller)) {
// Record the call relationship
callEdges.computeIfAbsent(caller, k -> new HashSet<>()).add(callee);
// Record the call relationship to CSV
long callerId = Math.abs(caller.hashCode());
long calleeId = Math.abs(callee.hashCode());
CsvWriter.addCalls(callerId, calleeId);
// Parse the complete call chain (e.g. a().b().c())
List<String> chain = new ArrayList<>();
CtInvocation<?> current = invocation;
while (current != null) {
chain.add(0, getInvocationSignature(current));
current = current.getTarget() instanceof CtInvocation ?
(CtInvocation<?>) current.getTarget() : null;
}
callChains.add(chain);
}
} catch (Exception e) {
log.error("Method Call process Error", e);
}
}This code highlights:
- Extract the complete signatures of the caller and callee
- Build the call relationship graph (callEdges)
- Identify and record method call chains (e.g. chain calls)
- Use hash values as method IDs to ensure consistency
3.3.2 Class Relationship Analysis
ClassRelationProcessor is responsible for analyzing the inheritance and implementation relationships between classes:
public void process(CtClass<?> ctClass) {
if (ctClass.getPosition().getFile() != null) {
// Inheritance relationship
if (ctClass.getSuperclass() != null) {
String superClassName = ctClass.getSuperclass().getQualifiedName();
// Record the call relationship to CSV
long childClassId = Math.abs(ctClass.getQualifiedName().hashCode());
long superClassId = Math.abs(superClassName.hashCode());
CsvWriter.addExtends(childClassId, superClassId);
// Other processing...
}
}
// Interface implementation
ctClass.getSuperInterfaces().forEach(i -> {
// Process interface implementation relationship
long superClassId = Math.abs(i.getQualifiedName().hashCode());
CsvWriter.addImplements(
Math.abs(ctClass.getQualifiedName().hashCode()),
Math.abs(i.getQualifiedName().hashCode())
);
// Other processing...
});
}This code demonstrates how:
- Identify class inheritance relationships
- Identify interface implementation relationships
- Store these relationships as edges in the graph database
3.3.3 Package Dependency Analysis
ReferenceProcessor is used to detect package dependencies, especially circular dependencies:
public void process(CtPackage element) {
CtPackageReference pack = element.getReference();
Set<CtPackageReference> refs = new HashSet<>();
for (CtType t : element.getTypes()) {
List<CtTypeReference<?>> listReferences = Query.getReferences(t,
new ReferenceTypeFilter<>(CtTypeReference.class));
for (CtTypeReference<?> tref : listReferences) {
if (tref.getPackage() != null && !tref.getPackage().equals(pack)) {
if (ignoredTypes.contains(tref))
continue;
refs.add(tref.getPackage());
}
}
}
if (!refs.isEmpty()) {
packRefs.put(pack, refs);
}
}
// Detect circular dependencies
@Override
public void processingDone() {
for (CtPackageReference p : packRefs.keySet()) {
Stack<CtPackageReference> path = new Stack<>();
path.push(p);
scanDependencies(path);
}
}This code highlights:
- Collect package references
- Use depth-first search to detect circular dependencies
- Record the discovered circular dependency paths
3.4 API Endpoint Identification
APIEndpointProcessor is specifically designed to identify REST API endpoints:
public void process(CtMethod<?> method) {
// Basic information of the method
String methodName = method.getDeclaringType().getQualifiedName() + "." + method.getSimpleName();
String methodFullName = /* Build the complete method signature */;
String comment = CommentExtractor.extractComment(method);
long methodId = Math.abs(methodFullName.hashCode());
long classId = Math.abs(method.getDeclaringType().getQualifiedName().hashCode());
// API endpoint processing
for (Class<? extends Annotation> annotation : MAPPING_ANNOTATIONS) {
if (methodMap.containsKey(methodFullName) && classIdMap.containsKey(classId)) {
if (method.getAnnotation(annotation) != null) {
String path = extractPathFromAnnotation(method, annotation);
long apiEndpointId = Math.abs((path + "|" + methodName).hashCode());
CsvWriter.addApiEndpoint(apiEndpointId, path, methodName, comment);
CsvWriter.addTriggers(apiEndpointId, methodId);
CsvWriter.addExposes(classId, apiEndpointId);
// Control flow analysis
if (method.getBody() != null) {
ControlFlowBuilder builder = new ControlFlowBuilder();
// Configure control flow analysis options
EnumSet<NaiveExceptionControlFlowStrategy.Options> options;
options = EnumSet.of(NaiveExceptionControlFlowStrategy.Options.ReturnWithoutFinalizers);
builder.setExceptionControlFlowStrategy(new NaiveExceptionControlFlowStrategy(options));
ControlFlowGraph graph = builder.build(method);
}
break;
}
}
}
}This code demonstrates how:
- Identify various mapping annotations of Spring MVC (e.g. @RequestMapping, @GetMapping, etc.)
- Extract API path information
- Establish the relationship between API endpoints and methods
- Analyze the control flow of API methods
3.5 Code Quality Detection
The system includes multiple processors for code quality detection:
3.5.1 Empty Catch Block Detection
public class CatchProcessor extends AbstractProcessor<CtCatch> {
public final List<CtCatch> emptyCatchs = new ArrayList<>();
@Override
public boolean isToBeProcessed(CtCatch candidate) {
return candidate.getBody().getStatements().isEmpty();
}
@Override
public void process(CtCatch element) {
getEnvironment().report(this, Level.INFO,
"empty catch clause at " + element.getPosition().toString());
emptyCatchs.add(element);
}
}3.5.2 Empty Method Body Detection
public class EmptyMethodBodyProcessor extends AbstractProcessor<CtMethod<?>> {
public final List<CtMethod> emptyMethods = new ArrayList<>();
public void process(CtMethod<?> element) {
if (element.getParent(CtClass.class) != null &&
!element.getModifiers().contains(ModifierKind.ABSTRACT) &&
element.getBody().getStatements().isEmpty()) {
emptyMethods.add(element);
}
}
}3.5.3 Factory Pattern Usage Detection
public class FactoryProcessor extends AbstractProcessor<CtConstructorCall<?>> {
public List<CtConstructorCall> listWrongUses = new ArrayList<>();
private CtTypeReference factoryTypeRef;
// Detect if the factory is bypassed by directly using the constructor
public void process(CtConstructorCall<?> newClass) {
// Skip factory creation
if (newClass.getExecutable().getDeclaringType().isSubtypeOf(getFactoryType()))
return;
// Skip creation in the factory
if (newClass.getParent(CtClass.class).isSubtypeOf(getFactoryType()))
return;
// Only report types that should be created by factories
for (CtTypeReference<?> t : getCreatedTypes()) {
if (newClass.getType().isSubtypeOf(t)) {
this.listWrongUses.add(newClass);
}
}
}
}These processors together constitute the code quality detection functionality of the system, helping development teams identify potential code issues.
4. Data Processing and Visualization
This section will detail the data processing and visualization方案,包括CSV数据存储格式、图数据库模型设计、数据导入转换过程以及可视化展示方案。
4.1 CSV Data Storage Format
The system uses CSV as an intermediate data storage format, with the CsvWriter class writing analysis results to CSV files. This format is simple and universal,便于调试和后续处理。
4.1.1 CSV File Structure
The system generates CSV files in two categories:
-
节点表:存储实体信息
module.csv:模块信息class.csv:类信息method.csv:方法信息apiendpoint.csv:API端点信息
-
关系表:存储实体间的关系
belongs_to.csv:类-模块关系has_method.csv:类-方法关系calls.csv:方法调用关系extends.csv:类继承关系implements.csv:接口实现关系exposes.csv:类-API端点关系triggers.csv:API端点-方法关系
4.1.2 CsvWriter实现
CsvWriter类负责将分析结果写入CSV文件,其核心实现如下:
public class CsvWriter {
private static final Map<String, List<String[]>> csvData = new HashMap<>();
static {
csvData.put("Module", new ArrayList<>());
csvData.put("Class", new ArrayList<>());
csvData.put("Method", new ArrayList<>());
csvData.put("APIEndpoint", new ArrayList<>());
csvData.put("BELONGS_TO", new ArrayList<>());
csvData.put("HAS_METHOD", new ArrayList<>());
csvData.put("CALLS", new ArrayList<>());
csvData.put("EXTENDS", new ArrayList<>());
csvData.put("IMPLEMENTS", new ArrayList<>());
csvData.put("EXPOSES", new ArrayList<>());
csvData.put("TRIGGERS", new ArrayList<>());
}
// 添加节点和关系的方法
public static void addClass(long classId, String className, String packageName,
String type, String comment, String filePath) {
csvData.get("Class").add(new String[]{
String.valueOf(classId), className, packageName, type, comment, filePath
});
}
// 其他添加方法...
// 写入所有CSV文件
public static void writeAll(Path outputDir) throws Exception {
for (String table : csvData.keySet()) {
Path file = outputDir.resolve(table.toLowerCase() + ".csv");
try (BufferedWriter writer = new BufferedWriter(new FileWriter(file.toFile()))) {
// 写入表头
switch (table) {
case "Class":
writer.write("class_id,class_name,package_name,type,comment,file_path\n");
break;
// 其他表头...
}
// 写入数据
for (String[] row : csvData.get(table)) {
writer.write(Arrays.stream(row)
.map(f -> f.contains(",") ? "\"" + f + "\"" : f)
.collect(Collectors.joining(",")) + "\n");
}
}
}
}
}CsvWriter采用了内存缓冲的设计,所有分析结果首先存储在内存中的Map结构里,分析完成后一次性写入文件,这种设计提高了性能并简化了实现。
4.2 图数据库模型设计
系统使用KuzuDB作为图数据库,将代码结构和关系表示为图模型。
4.2.1 节点表设计
图数据库中定义了四种主要节点类型:
# 模块节点
conn.execute(
"CREATE NODE TABLE IF NOT EXISTS Module (module_id INT64, module_name STRING, project_path STRING, PRIMARY KEY (module_id))"
)
# 类节点
conn.execute(
"CREATE NODE TABLE IF NOT EXISTS Class(class_id INT64, class_name STRING, package_name STRING, type STRING, comment STRING, file_path STRING, PRIMARY KEY(class_id))"
)
# 方法节点
conn.execute(
"CREATE NODE TABLE IF NOT EXISTS Method(method_id INT64, method_full_name STRING, return_type STRING, modifiers STRING, comment STRING, start_line STRING, end_line STRING, PRIMARY KEY(method_id))"
)
# API端点节点
conn.execute(
"CREATE NODE TABLE IF NOT EXISTS APIEndpoint(api_endpoint_id INT64, endpoint_url STRING, method_full_name STRING, description STRING, PRIMARY KEY(api_endpoint_id))"
)每种节点类型都有其特定属性,如:
- Module:模块ID、名称、项目路径
- Class:类ID、类名、包名、类型、注释、文件路径
- Method:方法ID、完整方法名、返回类型、修饰符、注释、起始行、结束行
- APIEndpoint:端点ID、URL路径、方法全名、描述
4.2.2 关系表设计
图数据库中定义了七种主要关系类型:
# 类属于模块
conn.execute("CREATE REL TABLE IF NOT EXISTS BELONGS_TO (FROM Class TO Module)")
# 类拥有方法
conn.execute("CREATE REL TABLE IF NOT EXISTS HAS_METHOD (FROM Class TO Method)")
# 方法调用方法
conn.execute("CREATE REL TABLE IF NOT EXISTS CALLS (FROM Method TO Method)")
# 类继承类
conn.execute("CREATE REL TABLE IF NOT EXISTS EXTENDS (FROM Class TO Class)")
# 类实现接口
conn.execute("CREATE REL TABLE IF NOT EXISTS IMPLEMENTS (FROM Class TO Class)")
# 类暴露API端点
conn.execute("CREATE REL TABLE IF NOT EXISTS EXPOSES (FROM Class TO APIEndpoint)")
# API端点触发方法
conn.execute("CREATE REL TABLE IF NOT EXISTS TRIGGERS (FROM APIEndpoint TO Method)")这些关系构成了代码结构的完整图谱,可以回答诸如”哪些方法调用了特定方法”、“特定API端点触发了哪些方法”等复杂查询。
4.3 数据导入与转换
系统使用Python脚本create_graph.py将CSV数据导入KuzuDB图数据库:
import shutil
import kuzu
DB_PATH = "./kuzudb"
shutil.rmtree(DB_PATH, ignore_errors=True)
db = kuzu.Database(DB_PATH)
conn = kuzu.Connection(db)
# 创建节点和关系表
# ...(前面已展示)
# 导入CSV数据
conn.execute(
"COPY Module FROM '/path/to/output/module.csv' (HEADER=true)"
)
conn.execute(
"COPY Class FROM '/path/to/output/class.csv' (HEADER=true)"
)
# 其他表导入...
print(f"Finished processing data and created Kuzu graph at the following path: {DB_PATH}")导入过程的关键点:
- 首先清空并重新创建数据库目录
- 创建数据库连接
- 定义节点和关系表结构
- 使用COPY命令从CSV文件批量导入数据
这种设计使得Java分析部分和图数据库构建部分解耦,便于独立开发和维护。
4.4 可视化展示方案
基于KuzuDB图数据库,系统可以支持多种可视化展示方案:
4.4.1 调用关系图
方法调用关系可以通过以下Cypher查询获取并可视化:
MATCH (caller:Method)-[:CALLS]->(callee:Method)
RETURN caller.method_full_name AS source, callee.method_full_name AS target这种查询可以生成方法调用网络图,展示方法间的调用关系。下图展示了一个实际项目的方法调用关系可视化效果:
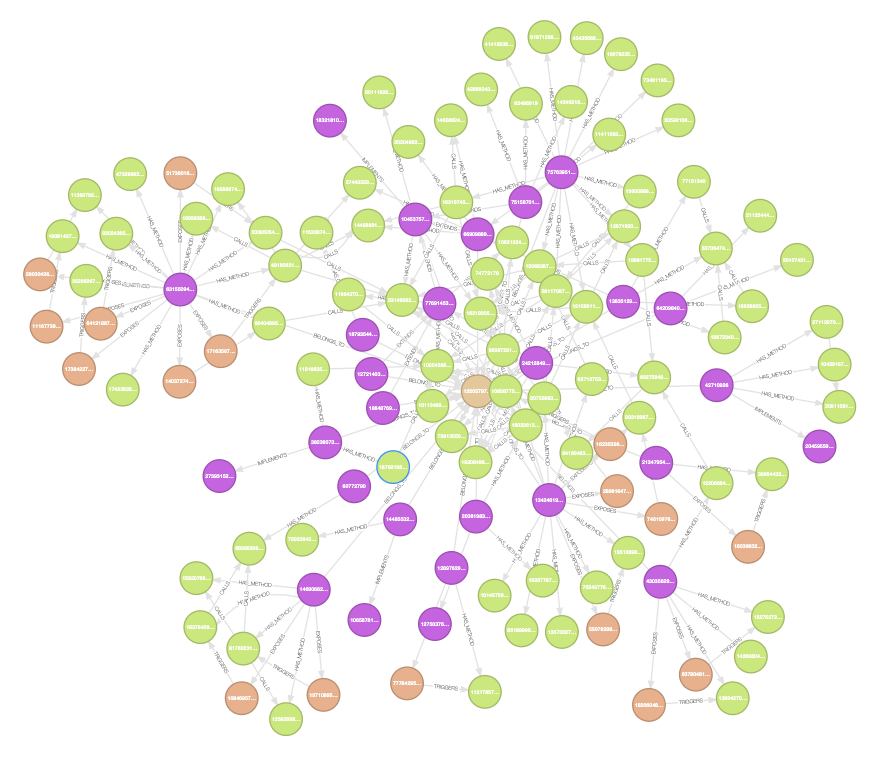
图4-1:Java代码方法调用关系可视化。不同颜色的节点代表不同类型的方法,连线表示调用关系。
4.4.2 类继承树
类继承关系可以通过以下Cypher查询获取并可视化:
MATCH (child:Class)-[:EXTENDS]->(parent:Class)
RETURN child.class_name AS child, parent.class_name AS parent这种查询可以生成类继承树,展示类的层次结构。
4.4.3 API依赖图
API端点及其依赖的方法可以通过以下Cypher查询获取:
MATCH (api:APIEndpoint)-[:TRIGGERS]->(method:Method)
RETURN api.endpoint_url AS api_url, method.method_full_name AS method_name这种查询可以生成API依赖图,展示API端点与后端方法的关系。
4.4.4 模块依赖图
模块间的依赖关系可以通过类间调用关系推导:
MATCH (c1:Class)-[:BELONGS_TO]->(m1:Module),
(c2:Class)-[:BELONGS_TO]->(m2:Module),
(c1)-[:HAS_METHOD]->(caller:Method),
(c2)-[:HAS_METHOD]->(callee:Method),
(caller)-[:CALLS]->(callee)
WHERE m1.module_id <> m2.module_id
RETURN m1.module_name AS source_module,
m2.module_name AS target_module,
count(*) AS dependency_strength这种查询可以生成模块依赖热力图,展示模块间的依赖强度。
通过这些可视化方案,开发团队可以直观地理解代码结构、依赖关系和潜在问题,为代码优化和重构提供依据。
5. 附录:运行KuzuDB可视化界面
为了方便查看和探索代码分析结果,KuzuDB提供了一个名为KuzuDB Explorer的可视化界面工具。以下是启动该工具的Docker命令:
docker run -p 8000:8000 \
-v ./kuzudb:/database \
--rm kuzudb/explorer:latest该命令会:
- 在本地8000端口启动KuzuDB Explorer
- 将本地的
./kuzudb目录挂载到容器的/database路径 - 容器停止后自动删除(
--rm参数)
启动后,可以通过浏览器访问http://localhost:8000来使用可视化界面,执行Cypher查询并查看结果图形。